近几年,供应链物流+AI特别火,但大家却越卷越累。多智能体、大模型、知识图谱……行业里大家都在比:谁家的Agent多,谁家的参数大,谁家的架构复杂。
但你有没有发现一个尴尬的现象:上了好几个Agent,用了最贵的模型,结果AI回答问题的准确率还是上不去。问它“哪些是滞销品”,它给你返回了一个SQL语句,语法全对,但查出来的东西根本不是你要的。问它“某渠道发货为什么慢了”,它分析了一大堆,最后结论是错的。
这不是你一家的问题。
最近LOGResearch Agent发布的《供应链本体+多Agent架构最佳实践对比研究》研究了三个真实案例——来自UC Berkeley、剑桥大学和AWS/Amazon,覆盖从知识表示、图谱构建到智能体编排的完整技术栈,代表了当前全球供应链数字化智能化的最高水平(可点击文末“阅读原文”查看完整版报告)。报告指出一个被大多数人忽视的真相:决定AI系统准不准的,不是Agent有多少个,也不是模型有多大,而是一个叫“语义层”的东西。
它就是系统的天花板——语义层什么样,AI的准确率就到哪,其设计质量直接限制了系统的业务准确性上限。报告直接指出,语义层缺陷的修复成本远高于下游组件的调优成本。语义层设计应作为系统建设的首要投入方向,而非在实体建模或智能体开发之后再补课。
简单说,地基没打好,上面盖什么都是危房。
01
什么是语义层?
先别被这个词吓到。打个比方就懂了。
你公司的业务人员说人话:“帮我看看上个月哪些SKU是滞销品?”数据库听不懂人话,它只懂SQL语句,比如“SELECT * FROM inventory WHERE turnover_days > 90”。
中间缺一个翻译官——把“滞销品”这三个字,准确地翻译成数据库能执行的查询条件。
这个翻译官,就叫语义层。
听起来很简单,对吧?但恰恰是这一层,大多数企业没做好。
报告里举了一个Amazon的真实案例。Amazon的团队发现,AI最容易出错的地方,不是SQL写错了,而是根本听不懂业务术语。比如“滞销品”,不同团队、不同渠道定义完全不一样:有的认为是90天没卖出去,有的认为是库存周转天数超过90天。如果不明确告诉AI,它就会瞎猜,猜出来的SQL语法正确,但业务上完全不可用。
Amazon统计过一个数字:业务术语理解错误,占了所有AI错误的40%以上。
这不是技术问题,这是翻译问题。
02
三个前沿案例实践,三种翻译方式
报告研究了三种不同的翻译方式,各有优缺点。
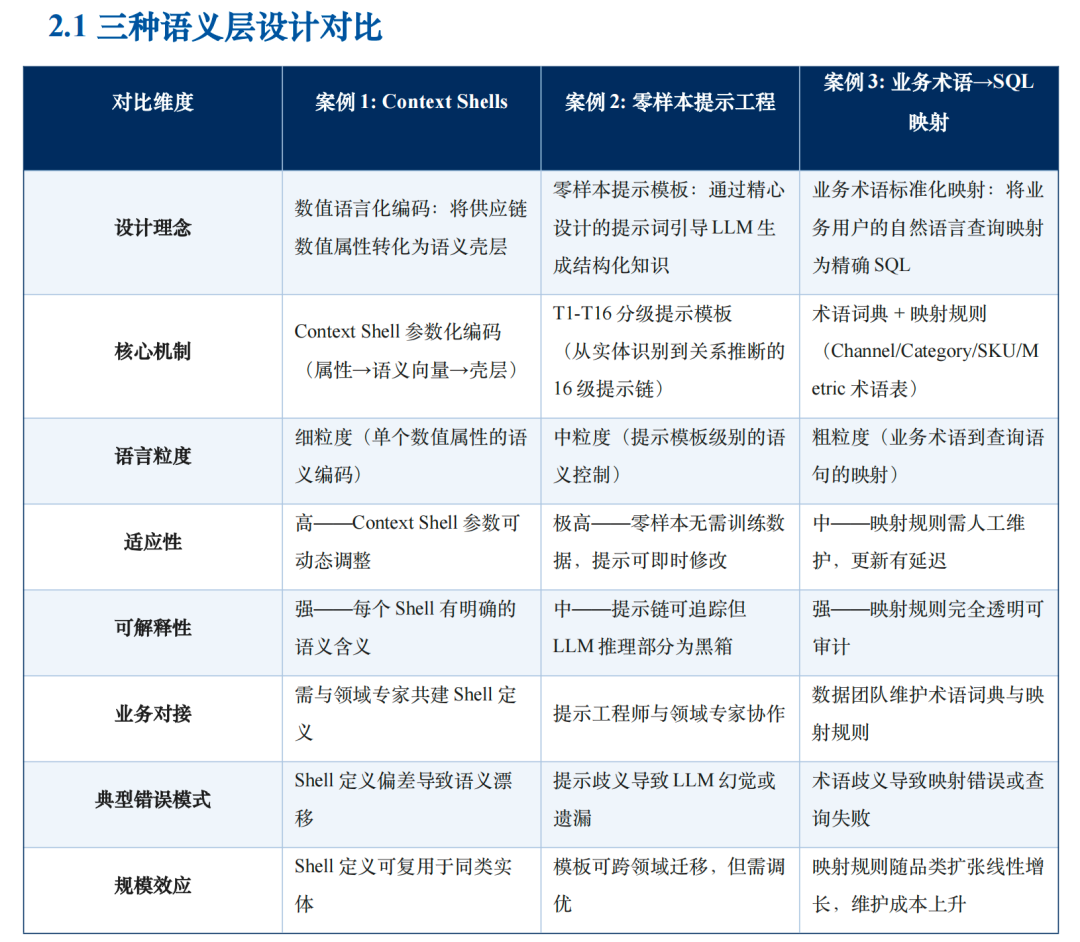
第一种:UC Berkeley + MSCI 的做法——Context Shells
核心是Context Shell,他们不直接扔数字给AI,而是把每个数字包在一段人话里。比如,不写“营收占比10%”,而是写“Apple的台式机营收占比为10%,其中19%的生产成本来自集成电路,13% 产自上海……”
这样AI看到的不再是冷冰冰的数字,而是带解释的完整故事,让 LLM 理解数值背后的业务逻辑,解决大模型读数字无感的痛点。准确率提高了很多,但需要人工设计这些故事模板。
第二种:剑桥大学的做法——零样本提示工程
该方法论是,不给AI任何例子,只给定义,直接告诉 AI 规则:“公司”是什么,“供应商”是什么,“原材料”是什么……相当于给AI一本供应链字典,让它自己去文本里识别,去翻译、自己找关系。
这种方法适合从零开始、没有历史数据的场景。但缺点是准确率有波动,尤其在处理复杂供应关系时,准确率往往只能维持在 70% 左右。
第三种:Amazon的做法,叫术语——SQL映射
前文也提及AI智能体最容易出错的地方是根本听不懂业务术语,因此Amazon用了最“笨”但也最管用的一招:把所有的业务术语写成数学公式,直接绑定确定性 SQL表达式。比如“什么是滞销品?”“什么是发货完成率?”诸如此类的,全部转化成标准的SQL条件代码存在后台。
业务人员用自然语言提问,Agent像查表一样执行命令,自动生成精准查询,避免自由理解导致的错误。比如定义“滞销品 = 库存周转天数 > 90”,只要周转天数超过 90 天,它就断定这是滞销品错误率。这也将Agent业务术语理解错误率从40%直接降到接近0。
报告给了一个很实在的建议:新项目从零开始时,可以先用第二种零样本,快速搭起来;进入正式生产后,慢慢向第三种确定性映射靠拢。不要一开始就追求完美,也别一直依赖AI的黑盒推理。
03
多智能体不是越多越好,架构要匹配场景
当语义与本体落地,智能体架构决定执行效率。但很多企业一听说多智能体,就觉得Agent越多越牛。结果系统复杂到没人能维护,Agent之间互相打架,反而更慢。
报告里用三个案例讲清楚了,什么场景用什么架构,别瞎堆,分工决定成败。
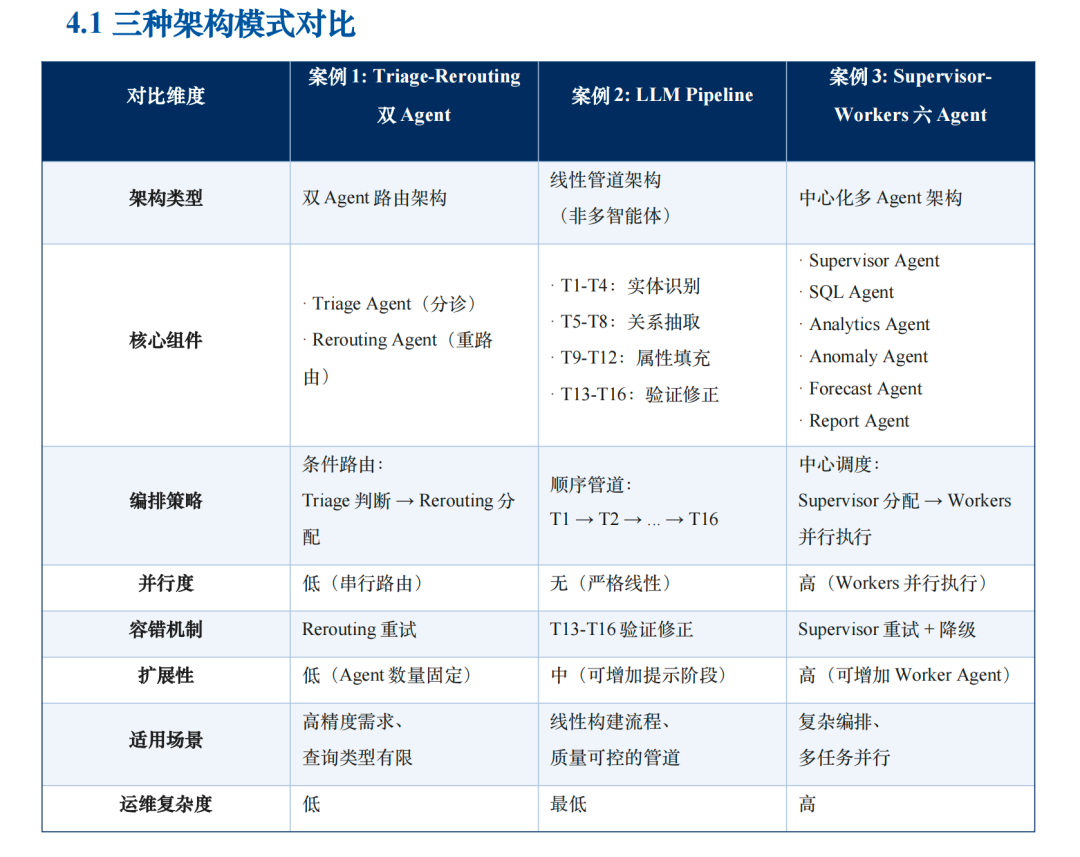
针对简单查询、高确定性场景,比如查一下某SKU的库存:用最简单的双Agent路由架构就够了。一个Agent判断问题类型,另一个Agent去查。跳数最少,响应最快。
针对线性构建流程化任务,用线性管道Pipeline架构就行,一个接一个做,不需要复杂调度。
针对复杂分析、多任务并行场景,比如“这个月各渠道履约表现怎么样?哪里有问题?为什么?怎么办?”等问题:用“主管+工人”架构(Supervisor-Workers)。一个主管Agent拆任务,下面挂一群专业工人,查数据的、下钻分析的、找根因的、写报告的、发工单的。该架构近几年将在更多零售和制造企业落地。
Amazon就是这么干的。他们把每个Agent的职责分得非常清楚,每个Agent的“任务说明书”很短,所以准确率高。而且所有配置都写在文件里,业务规则变了直接改配置,不用重新写代码。
报告里提到一个关键数据:当AI的任务说明书超过2000个字时,准确率会下降15%—20%。所以别让一个Agent干太多事,拆开反而更准。
这也是Amazon在真实生产环境中踩过的七个坑之一,其他六条具体可自行查看报告《供应链本体+多Agent架构最佳实践对比研究》。总结来看,这7条血泪教训可以总结成一句话:在多智能体生产系统中,确定性比灵活性重要,可配置比可编程重要,能闭环比只展示重要。
04
给从业者的五条实操建议
报告还提炼了一套最佳实践,可以翻译成五条接地气的建议。
建议1:先建语义层,再谈Agent。
别急着堆 Agent。先拿三成的时间和预算去搞定语义层。如果底基没搭好,语义是乱的,后面做再多智能体也是在沙滩上盖楼,一推就倒。
建议2:用业务人员的话建语义层。
建语义层的时候,直接把运营、销售拉进会议室,大家当面对齐。到底什么是“滞销”?什么是“发货完成率”?指标口径定死了,再写进代码里。业务怎么定义,AI就怎么理解,这样出来的结果才不会一本正经地胡说八道。
建议3:架构别贪大,匹配场景就行。
简单问题就用简单办法。别为了显摆技术,强行上多智能体协同。杀鸡没必要用宰牛刀,匹配业务复杂度的架构,才是最省钱、最稳妥的架构。
建议4:能配置的就别写代码。
把业务规则、流程逻辑、触发条件都做成配置项。这样业务一旦变了,运营人员自己动动手就能改,不用回回都去求技术部排期。响应速度快,才是硬道理。
建议5:从一个具体的业务问题出发。
千万别先造出一堆Agent,再回头琢磨它们能干啥。得先问问自己:我到底要解决什么业务痛点?是库存周转慢了,还是转化率低了?目标明确了,Agent 该长什么样自然就清楚了。
05
语义层将升级为企业核心战略资产
总结来看,在供应链这个行业,业务准不准,是1;模型参数和Agent数量,都是后面的0。没有前面的1,后面再多0也没有意义。那个1,就是语义层。
它不是最性感的技术,也不是最容易拿到预算的方向。但它是所有AI能力能不能落地、能不能被业务团队真正信任的地基,也将成为供应链 AI 系统能力的核心差异化因素。
报告明确指出:语义层投入ROI远高于扩展Agent数量,作为连接技术与业务的唯一桥梁,它决定知识图谱的表达边界、决定智能体的决策精度、决定整个系统是否能真正理解供应链业务逻辑。
报告也预测,2027 年前供应链领域将出现行业级语义标准,语义层从技术工具升级为企业核心战略资产。因此,大家与其在模型竞赛里内卷,不如先花时间把业务术语一条条写清楚,把翻译官的角色建扎实,快速建立自身核心战略资产。
这,才是供应链AI从“演示”走向“真用”的唯一捷径。
如果你正在做供应链数字化、多智能体或知识图谱,正被AI准确率问题反复困扰,不妨点击文末“阅读原文”,查看《供应链本体+多Agent架构最佳实践对比研究》完整版报告。
这份报告基于UC Berkeley、剑桥大学、、AWS/Amazon三个真实落地案例的硬核对比,覆盖了从知识表示、图谱构建到智能体编排的完整技术栈,代表了当前全球供应链数字化智能化的最高水平,提炼出三种架构、七条生产教训、五步落地原则,帮你少踩大部分的坑。
来源 | LOGResearch Agent

上线!")






